
最近学习使用ImHex并对hp39gii的.hpprgm程序进行了一些逆向研究,目前已经取得很大的进展,先来介绍ImHex,ImHex是一个基于ImGUI的十六进制编辑器,集成了很强大的 Pattern Language(模式语言) ,利用这个模式语言,可以优雅地编写程序逆向分析二进制文件结构。
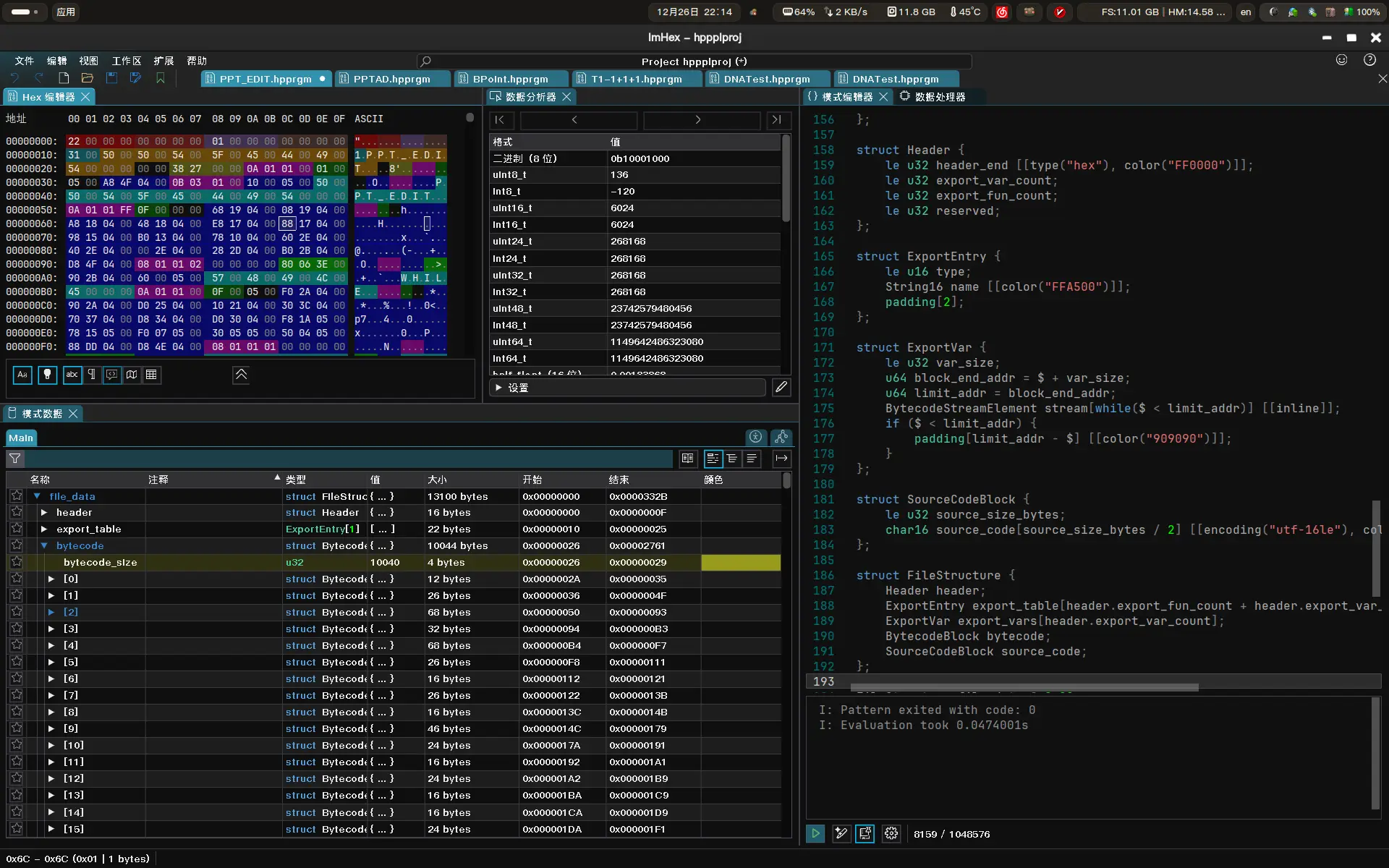
话不多说,让我们来看看这个HPPPL语言的.hppram文件格式吧!
首先以一个程序作为示例,HP39GII程序-图像处理库 BLib,这是一个带简单压缩算法的图像保存和加载库,我们在计算器上编辑好后,按下SHIFT+1【Prgm】之后,可以看到大小10KB,而实际上源码本身只有3KB,那么多出来的那些数据是什么呢?
1BLOAD�1BSAVE BREAK ,考虑到HPPPL语言如此高的执行效率,是否使用了某种类似编译的机制呢,为了深入分析,我们使用ImHex来查看: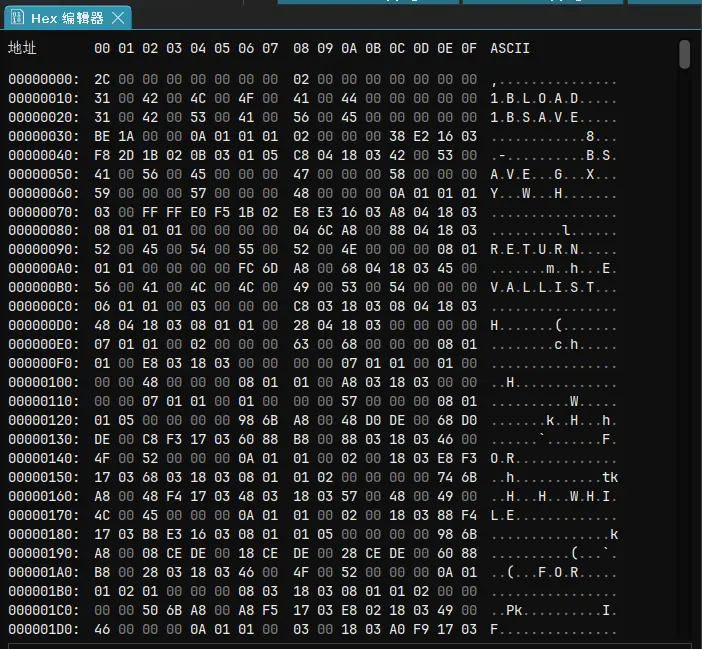
"BLOAD" 和 "BSAVE",两者正好对应程序对应的两个导出全局函数。结合 Header 结构体分析,0x08的02 即为导出函数的数量,在每个导出函数名称前,存在固定的标识符 0x31,可以推断,这代表该条目为“导出函数”类型。由于这部分数据呈现线性排列,我们将其定义为导出表。
接下来的分析可能比较难,通过对多个文件逆向对比分析发现,紧跟着导出函数列表后的4字节内容其实是导出列表到源代码区域的字节跨度,我称这一核心区域为BytecodeBlock。
实际上,该区域是由源代码编译而成的RPN(逆波兰表示法)堆栈字节码序列。也就是说,HP Prime 编程语言(HPPPL)在底层执行机制上,其实是基于栈式虚拟机架构的。
这里我直接给出最后的结果,文件的整体结构如下
struct FileStructure {
Header header; // 文件头
ExportEntry export_table[header.export_fun_count + header.export_var_count]; // 导出函数列表
ExportVar export_vars[header.export_var_count]; // 导出变量列表
BytecodeBlock bytecode; // 核心字节码区
SourceCodeBlock source_code; // 源码区域
};
FileStructure file_data @ 0x00; // 文件解析器开始位置,指向0x00
这是文件头的结构:
struct Header {
le u32 header_end [[type("hex"), color("FF0000")]];
le u32 export_var_count;
le u32 export_fun_count;
le u32 reserved;
};导出函数和变量的结构:
// 导出函数名是utf16编码,前16bit为type类型,最后有两字节的空余
struct ExportEntry {
le u16 type;
String16 name [[color("FFA500")]];
padding[2];
};
// 导出变量较为复杂,是使用了`RPN堆栈字节码序列`的
struct ExportVar {
le u32 var_size;
u64 block_end_addr = $ + var_size;
u64 limit_addr = block_end_addr;
BytecodeStreamElement stream[while($ < limit_addr)] [[inline]];
if ($ < limit_addr) {
padding[limit_addr - $] [[color("909090")]];
}
};面向对象的栈式虚拟机#
最关键的区域来了,BytecodeBlock实际上都是一系列的 OpcodeHeader + Bytecode
在常规语言(如 C 或 Java)的字节码中,指令(Opcode)和数据(Data/Constant Pool)通常是分离的。但在 HPPPL 的 BytecodeBlock 里,你会发现一个极其深刻的特点:指令本身就是对象的构造器,而数据本身就是可执行的指令。
让我们顺着这个思路往底层挖:
不难发现,在 BytecodeStreamElement 的 match 逻辑里,0x010104 指向的是一个矩阵,0x01030B 指向的是一个函数。最关键的来了:在虚拟机眼里,它们并没有本质区别。
- 在标准架构中:你会看到一条指令叫 PUSH_MATRIX [index]。
- 在 HPPPL 中:没有 PUSH 指令。当 BytecodeMatrix 结构出现在流中时,它本身就触发了“将自己实例化并压栈”的动作。
实际上,每一个 OpcodeHeader 并不是在描述“接下来是一个什么数据”,而是在定义一个 “自描述对象”。由于它是 RPN(逆波兰)架构,这种“万物即对象”的设计意味着:流里的每一个元素都是一个自包含的对象实例,它们被读取的那一刻,就完成了从二进制数据到运行时对象的转换。
// =====================================================================
// 迭代器核心:单条指令解析器
// =====================================================================
struct BytecodeStreamElement {
u64 limit = parent.limit_addr;
u32 peek_val = std::mem::read_unsigned($, 4);
u32 peek_opcode = peek_val & 0x00FFFFFF;
match (peek_opcode) {
// --- 数字字面量 (实数) ---
(0x000000 | 0x000100 | 0x010100 | 0x020100 | 0x030100): {
BytecodeNone bytecode_header;
u64 number [[color("FF0000"), comment("实数 (Double)")]];
}
// --- 字符串字面量 ---
(0x010102 | 0x020102): {
u32 byte_code [[color("FF00FF")]];
u16 str_len;
String16 str_val [[color("00FFFF")]];
}
// --- 复数/虚部字面量 ---
// 和0x000100一起出现
(0x010503): {
BytecodeNone bytecode_header;
u64 imag_number [[color("FF8000"), comment("虚部/复数数值")]];
}
// --- 矩阵 ---
(0x010104): {
BytecodeMatrix bitcode_matrix;
}
// --- 列表 / 向量 ---
(0x010106): {
BytecodeDirectory bytecode_dir;
}
// --- 变量 ---
(0x010107 | 0x020107 | 0x030107 | 0x360107 | 0x370107 | 0x400107 | 0x540107 | 0xE90107 | 0x990107): {
BytecodeNone bytecode_header;
String16 str_val [[color("00FFFF")]];
}
// --- 复杂调用结构 ---
(0x010108 | 0x010308): {
BytecodeNone bytecode_header;
}
// --- 单位 ---
(0x010109): {
u32 byte_code [[color("FF00FF")]];
u32 addr0;
u16 magic0;
String16 str_val [[color("00FFFF")]];
u24 magic1;
}
// --- 目录 ---
(0x01010A): {
BytecodeDirectory bytecode_dir;
}
// --- 函数定义 ---
(0x01030B | 0x01010B): {
BytecodeFunction function_def;
}
// --- 默认/未知指令处理 ---
(_): {
if ($ + 2 <= limit) {
le u16 unknown_instruction [[type("hex"), color("C0C0C0")]];
}
else {
u8 raw_byte [[color("505050")]];
}
}
}
};动态调试-深入分析#
随着对 BytecodeBlock 的解析日益清晰,一个更深层次的问题浮出水面:这些“对象”在内存中是如何被管理的?既然是栈式虚拟机,那么栈在哪里?系统函数(如 SIN, PRINT)又是如何被索引的?
通过对模拟器内存的动态调试(使用 IDA Pro 配合 ImHex),我发现了一个统管全局的结构体,该指针通常位于全局地址 dword_DECA00。我将其命名为 “上帝对象” (God Object) 或 VM Context。
实际上,HPPPL 虚拟机的运行状态并非离散的变量,而是封装在这个巨大的上下文结构中。我们可以将运行时的内存模型大致还原如下:
// 运行时核心结构:上帝对象
struct VM_Context {
u32 state_flags; // +0x00: 虚拟机状态标志
padding[0x14];
u32 user_env_ptr; // +0x18: 用户环境指针(指向用户定义的全局变量、导出函数)
u32 sys_env_ptr; // +0x1C: 系统环境指针(这是最关键的字典)
padding[0x354];
u32 sys_func_count; // +0x374: 内置系统函数数量
// ... 栈顶指针、堆内存池等
};
// 系统环境指针指向的“符号表”条目
struct SystemSymbolEntry {
u32 attributes; // 参数个数、返回类型
char* name_ptr; // 指向 "SIN", "PRINT" 等字符串
void* native_func_ptr; // 指向底层 C++ 实现代码 (.text段)
};这就解释了为什么在 BytecodeStreamElement 中,0x08 (Complex Call) 类型的对象只需要存储一个字符串名称(如 “SIN”)。
执行流程的真相:按名绑定(Late Binding)
当虚拟机解析到 0x08 类型的对象时,它并不是直接跳转,而是执行了一次动态查找:
- 压栈:将函数描述符入栈。
- 查表:拿着对象中的字符串 name,去 sys_env_ptr 指向的系统符号表中遍历。
- 调用:找到对应的 native_func_ptr,然后执行底层的 C++ 代码。
为了更直观地展示这种“万物即对象”与“RPN栈机”的结合,我们来还原一个经典场景:PRINT(SIN(1))。 在我们的 BytecodeBlock 中,这段代码会被序列化为以下对象流:
- 实数对象 (Type 00): 00 01 00 00 …
- 动作:直接入栈。此时栈顶:[1.0]。
- 函数调用对象 (Type 08): 08 01 00 03 “SIN”
- 动作:查表找到 math_sin。
- 执行:弹出 1.0,计算正弦值,结果 0.841 封装成新对象压栈。此时栈顶:[0.841]。
- 函数调用对象 (Type 08): 08 01 00 05 “PRINT”
- 动作:查表找到 io_print。
- 执行:弹出 0.841,调用图形接口绘制屏幕。
- 操作符对象 (Type 05): 05 00 00 0A (Statement End)
- 动作:这是一个特殊的“无负载”对象,ID 0A 告诉虚拟机语句结束,清理当前栈帧。
结论
至此,HPPPL 的全貌已然清晰:
它是以对象为基本图元,以 RPN 为执行逻辑,以动态符号表为链接桥梁的栈式虚拟机。
我们在文件中看到的每一个 OpcodeHeader,本质上都是一个冻结的对象。而虚拟机的任务,就是将这些冻结的对象解冻,扔进 VM_Context 维护的那个巨大的栈中,让它们相互作用,最终涌现出复杂的计算逻辑。
这也印证了我最初的猜想:HPPPL 并不是在“运行代码”,而是在“演化对象”。